The Dataset
Dataset 1+2 of the open competition contains recordings of 47 right-handed volunteers that provided 9477 equations overall. The task is to recognize single equations of unknown writers. Five labelled equations of each test-person can be used as adaptation set. Ground truths are complete equations (like 123+123=246), no character-segmentation is provided.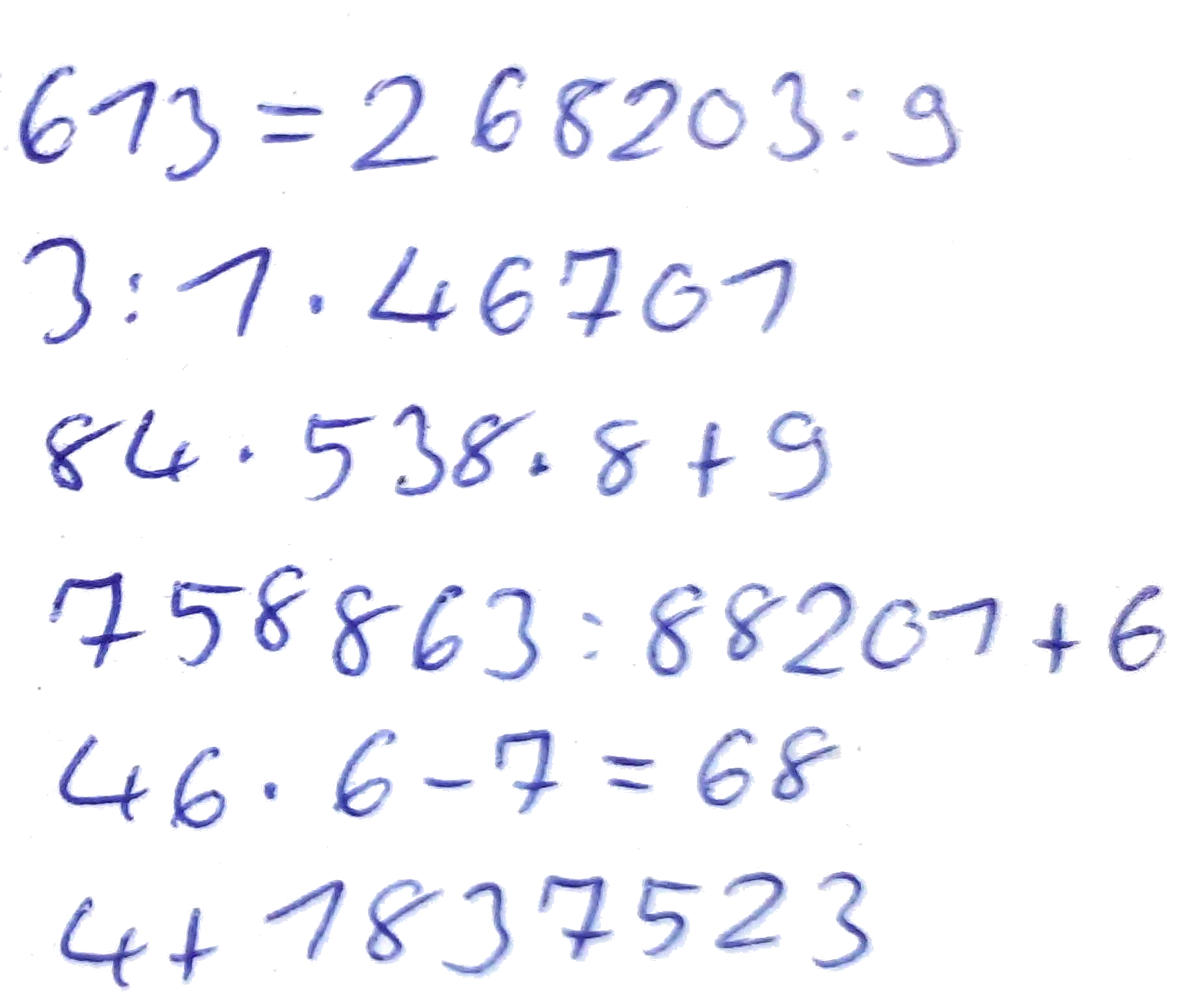
This is what you will be able to download after registering:
- A zipped folder containing 36 subfolders representing persons. Each person-folder contains one folder per recording of that person. Each recording-folder contains two files:
sensor_data.csv: Contains the raw time series data of a complete recording of two 3D accelerometers, a 3D gyroscope, a 3D magnetometer and a 1D force sensor sampled at 100 Hz. Furthermore, the last column of the file is a simple sample counter and the first column contains a timestamp indicating when the sample was transmitted to the recording device via Bluetooth. More info on the sensors.labels.csv: Contains the information at which point in time which equation was written. Thestartandstopcolumns of thelabels.csvfile point to theMilliscolumn in thesensor_data.csvfile.
- A Python 3 script
read_dataset.pythat splits thesensor_data.csvfile according to the timestamps given in the correspondinglabels.csvfile. It also saves the obtained letters and their labels in a pickle file for easier future use. Furthermore, the the code demonstrates how to split 5 equations off as an adaptation set. Look at this file’s source code to understand what’s going on in-depth.
Additional info on the dataset:
- There will be a second data release in ~May 2021 (having additional equations written by new volunteers)
- The equations are not segmented into the single characters they’re made up of
- The alphabet of the equations consists of the following characters:
Digits: 0,1,2,3,4,5,6,7,8,9
Operators: =,+,-,·,: (the last ones are used for multiplication/division in Germany) - The equations are not mathematically correct to prevent you from calculating the result
- It is not forbidden to use publicly available DigiPen data in addition to the challenge dataset but we do not encourage it.
How to evaluate?
- Your algorithm will be tested with data of secret writers.
- Your algorithm will receive 5 labelled equations of each secret writer right before the evaluation to automatically adapt your pipeline to this person’s gripping position and writing style.
- More info on what and how to submit can be found here.
Data Acquisition
To obtain the sensor data we provide for this challenge, we implemented a recording app that connects to a DigiPen and tells the volunteers which equation to write. These are some of the constraints that were met during the recordings:
- The recordings were conducted sitting on a chair in front of a table.
- The writing surface was horizontal.
- Normal, white paper sheets (about 80g/m^2) were used to write upon.
- The sheet was padded by five additional sheets.
- There was no guideline concerning the size of the handwriting. The subjects were asked to use a size that is natural for them.
- There was no guideline concerning the way of holding the pen. The subjects were asked to use a position that is natural for them.
- The volunteers were asked to make sure the STABILO logo faces up to avert different pen orientations.
- Participants could choose freely between print and cursive writing styles.
- Only right-handed recordings are released during this challenge.